
Data Governance Solutions
Data Governance is a policy framework that establishes a set of rules, processes and roles for collecting, storing and using data.
Most enterprises employ cyber security technologies to manage the “who” , “what " , “where” , “when” and " how” of data protection measures.
However, regulatory personal data governance frameworks ask “Why?..: What is the PURPOSE for collecting and processing personal data?”
In fact, unless you define the legitimate, specific, explicit purposes for collecting and processing personal data, you are not compliant with data protection regulations.
We provide solutions for a wide range of data governance requirements.
Data Discovery
Data discovery is a very important part of the data governance as you have to first find what you store and where you store them.
Discovering and classifying existing and future personal data is a prerequisite to privacy and data protection compliance.
Our solution can discover data both on structured, semi-structured and unstructured systems. Any database, including the noSQL, that has a JDBC connection feature is accessible by our solution. The tool comes with a number of mostly used data types (grammars) that can easily be selected and used. As already optimised after so many implementations discovery process is a very effective one having very low false-positive and false-negative results.
The results of the discovery can be reviwed via the GUI. The GUI is designed to be used by the business users and provide self explanatory screens.
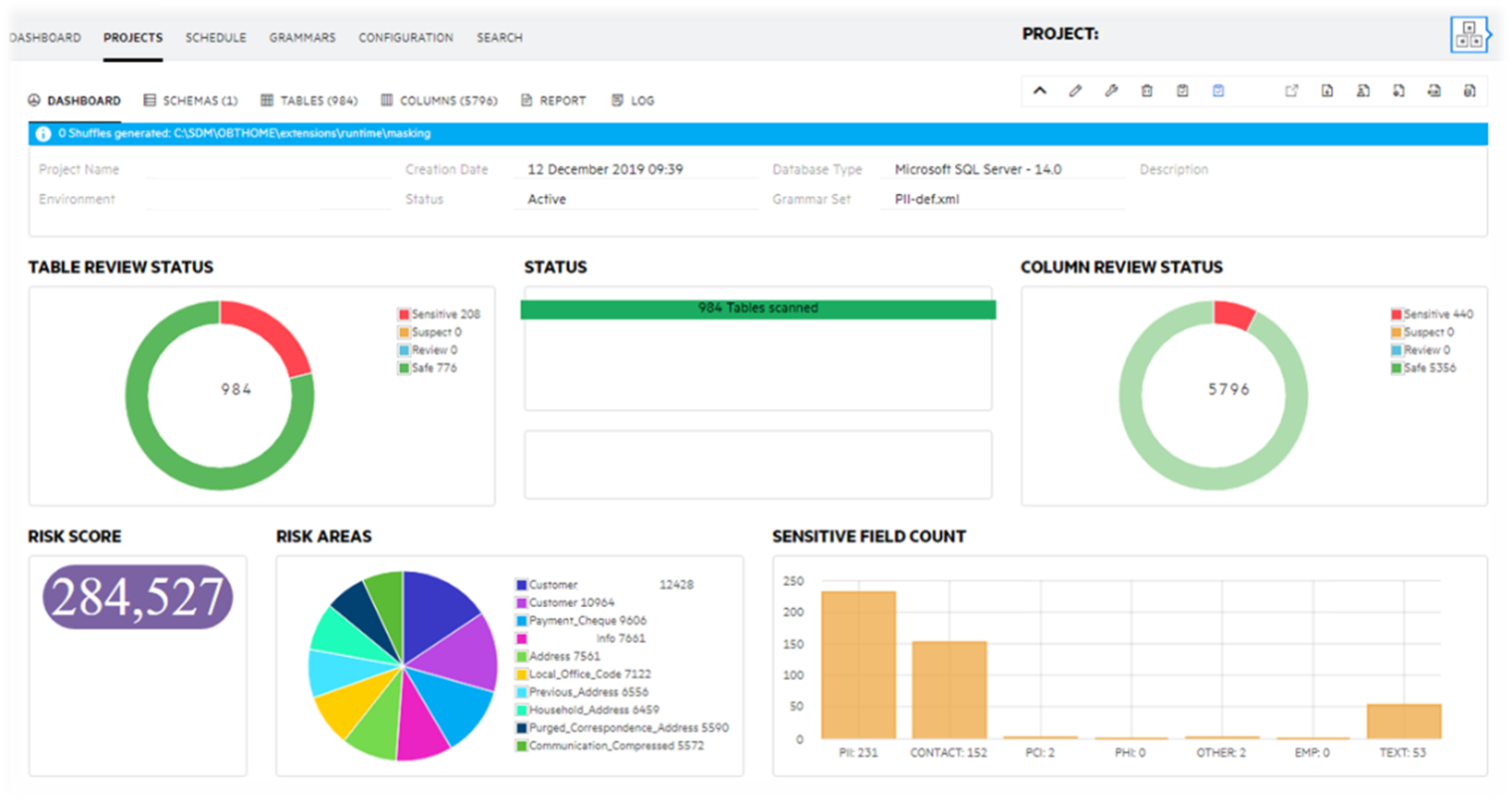
The discovery process can be scheduled, exclusions can be defined and a delta discovery is also possible saving time and effort as it discovers only the modified content. Both structured and unstructured discovery modules seriously contribute to the data minimisation efforts. Unreferenced tables (so called orphan tables) and ROT (Redundant, Obsolete and Trivial) documents can be discovered, reported and finally deleted to save IT platform resources.
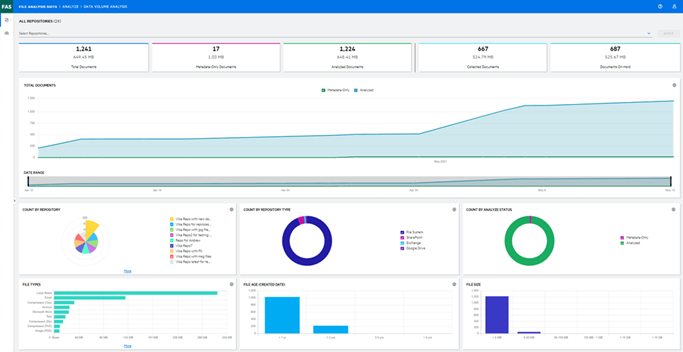
Database Archiving and Application Retirement
Organisations of all sizes are struggling to cope with application information growth. There is also increased complexity from tightening regulations, new database applications and legal discovery requirements. As these challenges intensify, so does the amount of customer data to manage and the length of time you are required to manage it.
Our solution:
- Archives data from primary or archive databases to vendor-neutral, industry-standard XML/CSV/JSON files for long-term retention that is independent of database version, originating application, operating system, and hardware.
- Combines database-to-database and database-to-file archiving, through multistage policies that migrate production data to secondary online archive databases. Then, as the data ages further, to XML, CSV, or JSON files.
- Runs enterprise reporting tools and standard SQL queries unchanged, directly against the file-based archive.
- Stores archived data in standard ASCII files on file systems, or on WORM or Content Addressable Storage systems.This function lets you choose your application data directly in the WebConsole for retiring. All you need to do is select the data to retire and then let the Retirement job run automatically.
The Designer provides a rich graphical interface for modeling application transactions and creating archive policies that extend archiving support to your third-party and custom applications. The data can also be manipulated for different purposes, including the data protection and compliancy, while archiving.
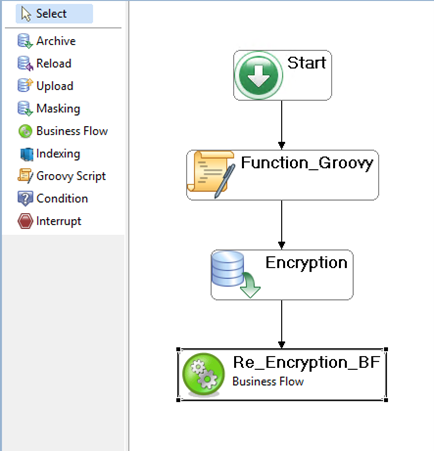
Test Data Management (TDM) and Database Migration
Due to the local and global regulations and data privacy legislations, organisations can no longer use production data for testing and development purposes. There should be right tools in place to create anonymised data for such purposes to avoid and compliancy risks like penalties or even worse, damage to the image of the organisation.
Here also the process begins with the data discovery to first find where the sensitive data is. Only then the protection actions can be implemented. Our solution provides the tools to extract the data from the production environments or even generate it synthetically.
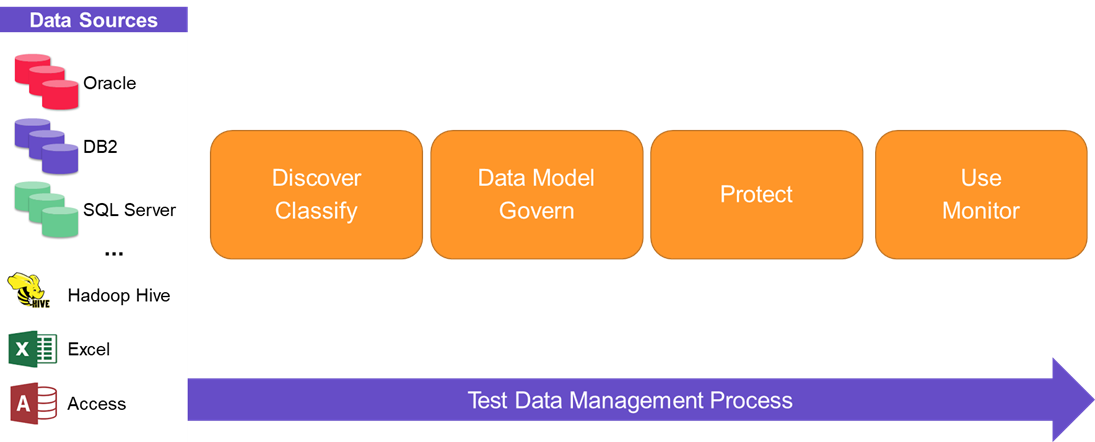
The same tool can be used to migrate data from the source environment (DB vendor A) to the destination (DB vendor B). The database fields are created automatically on the target environment to assist the whole migration process.
Technology Stack
Our technology stack to cover the generic data governance requirements comprises of following Opentext solutions;
- Structured Data Manager
- File Analysis Suite
Top